1. Stack Memory Vs Heap Memory
The heap
The heap (also known as the “free store”) is a large pool of memory used for dynamic allocation. In C++, when you use the new operator to allocate memory, this memory is assigned from the heap.
view source
print?
int *pValue = new int; // pValue is assigned 4 bytes from the heap
int *pArray = new int[10]; // pArray is assigned 40 bytes from the heap
Because the precise location of the memory allocated is not known in advance, the memory allocated has to be accessed indirectly — which is why new returns a pointer.
You do not have to worry about the mechanics behind the process of how free memory is located and allocated to the user. However, it is worth knowing that sequential memory requests may not result in sequential memory addresses being allocated!
view source
int *pValue1 = new int;
int *pValue2 = new int;
// pValue1 and pValue2 may not have sequential addresses
When a dynamically allocated variable is deleted, the memory is “returned” to the heap and can then be reassigned as future allocation requests are received.
The heap has advantages and disadvantages:
1) Allocated memory stays allocated until it is specifically deallocated (beware memory leaks).
2) Dynamically allocated memory must be accessed through a pointer.
3) Because the heap is a big pool of memory, large arrays, structures, or classes should be allocated here.
The stack
The call stack (usually referred to as “the stack”) has a much more interesting role to play. Before we talk about the call stack, which refers to a particular portion of memory, let’s talk about what a stack is.
Consider a stack of plates in a cafeteria. Because each plate is heavy and they are stacked, you can really only do one of three things:
1) Look at the surface of the top plate
2) Take the top plate off the stack
3) Put a new plate on top of the stack
In computer programming, a stack is a container that holds other variables (much like an array).
However, whereas an array lets you access and modify elements in any order you wish, a stack is more limited. The operations that can be performed on a stack are identical to the ones above:
1) Look at the top item on the stack (usually done via a function called top())
2) Take the top item off of the stack (done via a function called pop())
3) Put a new item on top of the stack (done via a function called push())
A stack is a last-in, first-out (LIFO) structure. The last item pushed onto the stack will be the first item popped off. If you put a new plate on top of the stack,
anybody who takes a plate from the stack will take the plate you just pushed on first. Last on, first off. As items are pushed onto a stack, the stack grows larger — as items are popped off, the stack grows smaller.
The plate analogy is a pretty good analogy as to how the call stack works, but we can actually make an even better analogy. Consider a bunch of mailboxes, all stacked on top of each other.
Each mailbox can only hold one item, and all mailboxes start out empty. Furthermore, each mailbox is nailed to the mailbox below it, so the number of mailboxes can not be changed. If we can’t change the number of mailboxes, how do we get a stack-like behavior?
First, we use a marker (like a post-it note) to keep track of where the bottom-most empty mailbox is.
In the beginning, this will be the lowest mailbox. When we push an item onto our mailbox stack, we put it in the mailbox that is marked (which is the first empty mailbox), and move the marker up one mailbox. When we pop an item off the stack, we move the marker down one mailbox and remove the item from that mailbox. Anything below the marker is considered “on the stack”. Anything at the marker or above the marker is not on the stack.
This is almost exactly analogous to how the call stack works. The call stack is a fixed-size chunk of sequential memory addresses. The mailboxes are memory addresses, and the “items” are pieces of data (typically either variables or addreses).
The “marker” is a register (a small piece of memory) in the CPU known as the stack pointer. The stack pointer keeps track of where the top of the stack currently is.
The only difference between our hypothetical mailbox stack and the call stack is that when we pop an item off the call stack, we don’t have to erase the memory (the equivalent of emptying the mailbox). We can just leave it to be overwritten by the next item pushed to that piece of memory. Because the stack pointer will be below that memory location, we know that memory location is not on the stack.
So what do we push onto our call stack? Parameters, local variables, and… function calls.
The stack in action
Because parameters and local variables essentially belong to a function, we really only need to consider what happens on the stack when we call a function. Here is the sequence of steps that takes place when a function is called:
1. The address of the instruction beyond the function call is pushed onto the stack. This is how the CPU remembers where to go after the function returns.
2. Room is made on the stack for the function’s return type. This is just a placeholder for now.
3. The CPU jumps to the function’s code.
4. The current top of the stack is held in a special pointer called the stack frame. Everything added to the stack after this point is considered “local” to the function.
5. All function arguments are placed on the stack.
6. The instructions inside of the function begin executing.
7. Local variables are pushed onto the stack as they are defined.
When the function terminates, the following steps happen:
1. The function’s return value is copied into the placeholder that was put on the stack for this purpose.
2. Everything after the stack frame pointer is popped off. This destroys all local variables and arguments.
3. The return value is popped off the stack and is assigned as the value of the function. If the value of the function isn’t assigned to anything, no assignment takes place, and the value is lost.
4. The address of the next instruction to execute is popped off the stack, and the CPU resumes execution at that instruction.
Typically, it is not important to know all the details about how the call stack works. However, understanding that functions are effectively pushed on the stack when they are called and popped off when they return gives you the fundamentals needed to understand recursion, as well as some other concepts that are useful when debugging.
Stack overflow
The stack has a limited size, and consequently can only hold a limited amount of information. I
If the program tries to put too much information on the stack, stack overflow will result.
Stack overflow happens when all the memory in the stack has been allocated — in that case, further allocations begin overflowing into other sections of memory.
Stack overflow is generally the result of allocating too many variables on the stack, and/or making too many nested function calls (where function A calls function B calls function C calls function D etc…) Overflowing the stack generally causes the program to crash.
Here is an example program that causes a stack overflow. You can run it on your system and watch it crash:
int main()
{
int nStack[100000000];
return 0;
}
This program tries to allocate a huge array on the stack. Because the stack is not large enough to handle this array, the array allocation overflows into portions of memory the program is not allowed to use. Consequently, the program crashes.
The stack has advantages and disadvantages:
Memory allocated on the stack stays in scope as long as it is on the stack. It is destroyed when it is popped off the stack.
All memory allocated on the stack is known at compile time. Consequently, this memory can be accessed directly through a variable.
Because the stack is relatively small, it is generally not a good idea to do anything that eats up lots of stack space. This includes allocating large arrays, structures, and classes, as well as heavy recursion.
Stack:
Stored in computer RAM like the heap.
Variables created on the stack will go out of scope and automatically deallocate.
Much faster to allocate in comparison to variables on the heap.
Implemented with an actual stack data structure.
Stores local data, return addresses, used for parameter passing
Can have a stack overflow when too much of the stack is used. (mostly from inifinite (or too much) recursion, very large allocations)
Data created on the stack can be used without pointers.
You would use the stack if you know exactly how much data you need to allocate before compile time and it is not too big.
Usually has a maximum size already determined when your program starts
Heap:
Stored in computer RAM like the stack.
Variables on the heap must be destroyed manually and never fall out of scope. The data is freed with delete, delete[] or free
Slower to allocate in comparison to variables on the stack.
Used on demand to allocate a block of data for use by the program.
Can have fragmentation when there are a lot of allocations and deallocations
In C++ data created on the heap will be pointed to by pointers and allocated with new or malloc
Can have allocation failures if too big of a buffer is requested to be allocated.
You would use the heap if you don't know exactly how much data you will need at runtime or if you need to allocate a lot of data.
Responsible for memory leaks
Can you overload new operator
#include<iostream>
#include<malloc.h>
using namespace std;
class sample
{
int i;
char c;
public:
void* operator new(size_t s,int ii,char cc)
{
sample *q =(sample*) malloc(s);
q->i =ii;
q->c =cc;
cout<<"Memory allocation"<<endl;
return q;
}
void operator delete(void *q)
{
free(q);
}
void display()
{ cout<<i<<" "<<c;
}
};
int main()
{
sample *s =new (7,'a')sample;
return 0;
}
when-do-you-overload-operator-new
What is mean of size_t and why we need it.
size_t is type of unsigned integer.which is the Return value of sizeof operator.
`size_t' is a type suitable for representing the amount of memory a data object requires, expressed in units of `char'.
It is an integer type (C cannot keep track of fractions of a `char'), and it is unsigned (negative sizes make no sense). It is the type of the result of the `sizeof' operator. It is the type you pass to malloc() and friends to say how much memory you want.
It is the type returned by strlen() to say how many "significant" characters are in a string.
Each implementation chooses a "real" type like `unsigned int' or `unsigned long' (or perhaps something else)
to be its `size_t', depending on what makes the most sense. You don't usually need to worry about what
`size_t' looks like "under the covers;" all you care about is that it is the "right" type for representing object sizes.
The implementation "publishes" its own choice of `size_t' in several of the Standard headers: <stdio.h>, <stdlib.h>, and some others. If you examine one of these headers (most implementations have some way of doing this), you are likely to find something like
#ifndef __SIZE_T
#define __SIZE_T
typedef unsigned int size_t;
#endif
.... meaning that on this particular implementation `size_t' is an `unsigned int'. Other implementations make other choices.
(The preprocessor stuff -- which needn't be in exactly the form shown here -- ensures that your program will contain only one `typedef' for `size_t' even if it includes several of the headers that declare it)
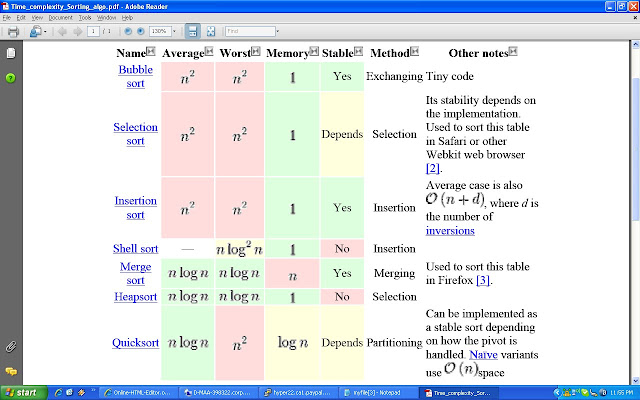
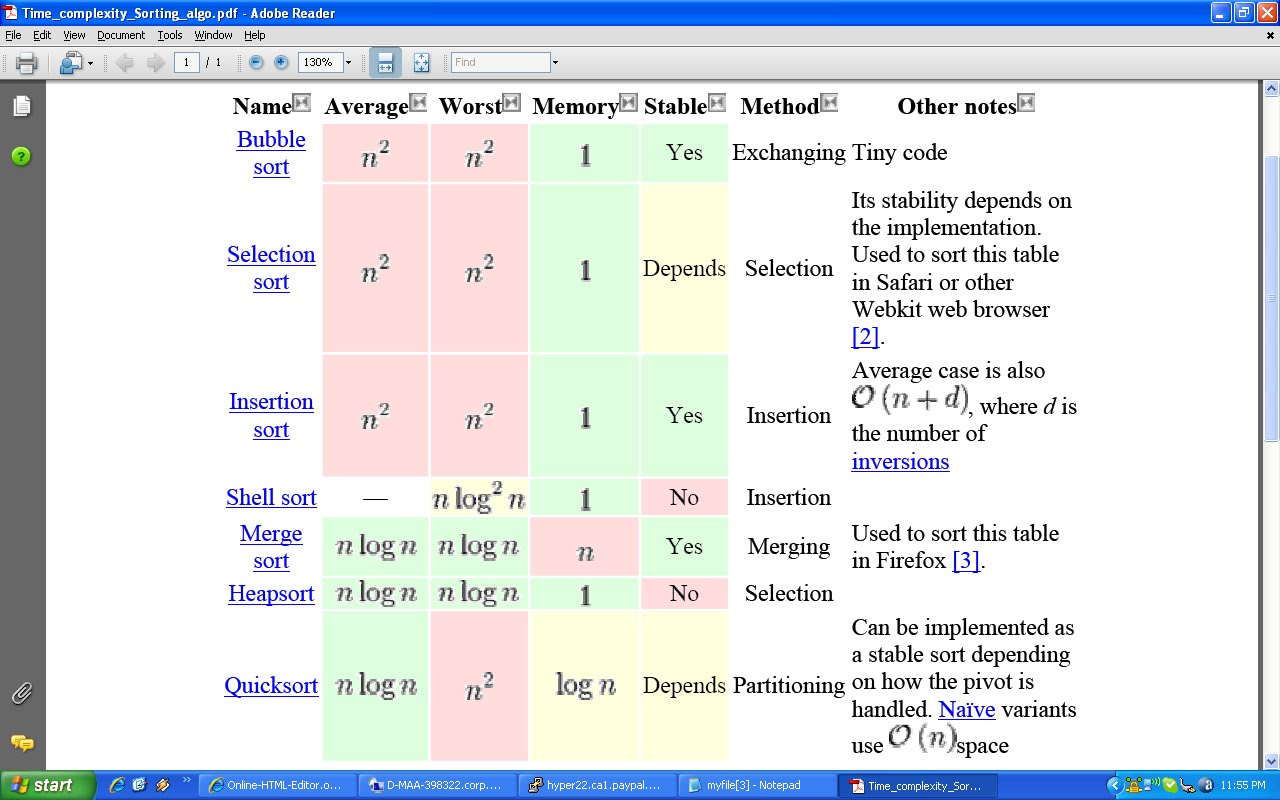
The complexity of sorting algorithm
Pointers, arrays, and string literals
void strtoupper(char *str)
{
if (str) { // null ptr check, courtesy of Michael
while (*str != '\0') {
// destructively modify the contents at the current pointer location
// using the dereference operator to access the value at the current
// pointer address.
*str = toupper(*str);
++str;
}
}
}
my_str is actually a pointer to a block of memory holding chars. This allows us to use address math to access indices of the array and modify them using the dereference operator. In fact, an array index such as my_str[3] is identical to the expression *(my_str + 3).
char my_str[] = "hello world";
*my_str = toupper(*my_str);
*(my_str + 6) = toupper(*(my_str + 6));
printf("%s", my_str); // prints, "Hello World"
However, if my_str is declared as a char pointer to the string literal “hello world” rather than a char array, these operations fail:
char *my_str = "hello world";
*my_str = toupper(*my_str); // fails
*(my_str + 6) = toupper(*(my_str + 6)); // fails
printf("%s", my_str);
Let’s explore the difference between the two declarations.
char *a = "hello world";
char b[] = "hello world";
In the compiled program, it is likely that “hello world” is stored literally inside the executable. It is effectively an immutable, constant value. Pointing char *a to it provides the scope with read-only access to an immutable block of memory. Therefore, attempting to assign a value might cause other code that points to the same memory to behave erratically.
The declaration of char b[] instead declares a locally allocated block of memory that is then filled with the chars, “hello world”. b is now a pointer to the first address of that array. The complete statement, combining the declaration and assignment, is shorthand. Dispensing with the array size (e.g., char instead of char[12]) is permitted as the compiler is able to ascertain its size from the string literal it was assigned.
In both cases the pointer is used to access array indices:
int i;
for (i = 0; a[i] != '\0'; ++i)
printf("%c", toupper(a[i]));
However, only with b is the program able to modify the values in memory, since it is explicitly copied to a mutable location on the stack in its declaration:
int i;
for (i = 0; b[i] != '\0'; ++i)
b[i] = toupper(b[i]);
printf("%s", b);
Binary Search
A fast way to search a sorted array is to use a binary search. The idea is to look at the element in the middle. If the key is equal to that, the search is finished. If the key is less than the middle element, do a binary search on the first half. If it's greater, do a binary search of the second half.
Performance
The advantage of a binary search over a linear search is astounding for large numbers. For an array of a million elements, binary search, O(log N), will find the target element with a worst case of only 20 comparisons. Linear search, O(N), on average will take 500,000 comparisons to find the element. Probably the only faster kind of search uses hashing, a topic that isn't covered in these notes.
This performance comes at a price - the array must be sorted first. Because sorting isn't a fast operation, it may not be worth the effort to sort when there are only a few searches.
int main()
{
char my_str[] = "hello world";
strtoupper(my_str);
printf("%s", my_str);
return 0;
}
Boost Libraries
The name should already give it away
A Smart Pointer is a C++ object that acts like a pointer, but additionally deletes the object when it is no longer needed.
You cannot pass a
You have to construct a smart pointer explicitly, which also makes it
clear that you transfer ownership of the raw pointer to the smart pointer. (See also Rule 3.)
Rule 2: No circular references
If you have two objects referencing each other through a reference counting pointer
they are never deleted. boost provides
Rule 3: no temporary shared_ptr
Do not construct temporary
always use a named (local) variable.
Cyclic References
Reference counting is a convenient resource management mechanism, it has one fundamental drawback though:
Reference counting is a convenient resource management mechanism, it has one fundamental drawback though:
struct CDad; struct CChild;
typedef boost::shared_ptr<CDad> CDadPtr;
typedef boost::shared_ptr<CChild> CChildPtr;
struct CDad : public CSample
{
CChildPtr myBoy;
};
struct CChild : public CSample
{
CDadPtr myDad;
};
// a "thing" that holds a smart pointer to another "thing":
CDadPtr parent(new CDadPtr);
CChildPtr child(new CChildPtr);
// deliberately create a circular reference:parent->myBoy = child;
child->myDad = dad;
Some Useful url related C++ FAQ
http://www.daniweb.com/forums/thread107723.html
// resetting one ptr...child.reset();
parent still references the
If we now call
But this leaves both with exactly one reference, and the shared pointers
see no reason to delete either of them! We have no access to them anymore but they mutually keep themselves "alive".
This is a memory leak at best; in the worst case, the objects hold even more critical resources
that are not released correctly.
The problem is not solvable with a "better" shared pointer implementation
or at least, only with unacceptable overhead and restrictions
So you have to break that cycle. There are two ways:
Manually break the cycle before you release your last reference to it
When the lifetime of
child can use a normal (raw) pointer to
Use a
Solutions (1) and (2) are no perfect solutions but they work with smart pointer libraries that do not offer a
The heap
The heap (also known as the “free store”) is a large pool of memory used for dynamic allocation. In C++, when you use the new operator to allocate memory, this memory is assigned from the heap.
view source
print?
int *pValue = new int; // pValue is assigned 4 bytes from the heap
int *pArray = new int[10]; // pArray is assigned 40 bytes from the heap
Because the precise location of the memory allocated is not known in advance, the memory allocated has to be accessed indirectly — which is why new returns a pointer.
You do not have to worry about the mechanics behind the process of how free memory is located and allocated to the user. However, it is worth knowing that sequential memory requests may not result in sequential memory addresses being allocated!
view source
int *pValue1 = new int;
int *pValue2 = new int;
// pValue1 and pValue2 may not have sequential addresses
When a dynamically allocated variable is deleted, the memory is “returned” to the heap and can then be reassigned as future allocation requests are received.
The heap has advantages and disadvantages:
1) Allocated memory stays allocated until it is specifically deallocated (beware memory leaks).
2) Dynamically allocated memory must be accessed through a pointer.
3) Because the heap is a big pool of memory, large arrays, structures, or classes should be allocated here.
The stack
The call stack (usually referred to as “the stack”) has a much more interesting role to play. Before we talk about the call stack, which refers to a particular portion of memory, let’s talk about what a stack is.
Consider a stack of plates in a cafeteria. Because each plate is heavy and they are stacked, you can really only do one of three things:
1) Look at the surface of the top plate
2) Take the top plate off the stack
3) Put a new plate on top of the stack
In computer programming, a stack is a container that holds other variables (much like an array).
However, whereas an array lets you access and modify elements in any order you wish, a stack is more limited. The operations that can be performed on a stack are identical to the ones above:
1) Look at the top item on the stack (usually done via a function called top())
2) Take the top item off of the stack (done via a function called pop())
3) Put a new item on top of the stack (done via a function called push())
A stack is a last-in, first-out (LIFO) structure. The last item pushed onto the stack will be the first item popped off. If you put a new plate on top of the stack,
anybody who takes a plate from the stack will take the plate you just pushed on first. Last on, first off. As items are pushed onto a stack, the stack grows larger — as items are popped off, the stack grows smaller.
The plate analogy is a pretty good analogy as to how the call stack works, but we can actually make an even better analogy. Consider a bunch of mailboxes, all stacked on top of each other.
Each mailbox can only hold one item, and all mailboxes start out empty. Furthermore, each mailbox is nailed to the mailbox below it, so the number of mailboxes can not be changed. If we can’t change the number of mailboxes, how do we get a stack-like behavior?
First, we use a marker (like a post-it note) to keep track of where the bottom-most empty mailbox is.
In the beginning, this will be the lowest mailbox. When we push an item onto our mailbox stack, we put it in the mailbox that is marked (which is the first empty mailbox), and move the marker up one mailbox. When we pop an item off the stack, we move the marker down one mailbox and remove the item from that mailbox. Anything below the marker is considered “on the stack”. Anything at the marker or above the marker is not on the stack.
This is almost exactly analogous to how the call stack works. The call stack is a fixed-size chunk of sequential memory addresses. The mailboxes are memory addresses, and the “items” are pieces of data (typically either variables or addreses).
The “marker” is a register (a small piece of memory) in the CPU known as the stack pointer. The stack pointer keeps track of where the top of the stack currently is.
The only difference between our hypothetical mailbox stack and the call stack is that when we pop an item off the call stack, we don’t have to erase the memory (the equivalent of emptying the mailbox). We can just leave it to be overwritten by the next item pushed to that piece of memory. Because the stack pointer will be below that memory location, we know that memory location is not on the stack.
So what do we push onto our call stack? Parameters, local variables, and… function calls.
The stack in action
Because parameters and local variables essentially belong to a function, we really only need to consider what happens on the stack when we call a function. Here is the sequence of steps that takes place when a function is called:
1. The address of the instruction beyond the function call is pushed onto the stack. This is how the CPU remembers where to go after the function returns.
2. Room is made on the stack for the function’s return type. This is just a placeholder for now.
3. The CPU jumps to the function’s code.
4. The current top of the stack is held in a special pointer called the stack frame. Everything added to the stack after this point is considered “local” to the function.
5. All function arguments are placed on the stack.
6. The instructions inside of the function begin executing.
7. Local variables are pushed onto the stack as they are defined.
When the function terminates, the following steps happen:
1. The function’s return value is copied into the placeholder that was put on the stack for this purpose.
2. Everything after the stack frame pointer is popped off. This destroys all local variables and arguments.
3. The return value is popped off the stack and is assigned as the value of the function. If the value of the function isn’t assigned to anything, no assignment takes place, and the value is lost.
4. The address of the next instruction to execute is popped off the stack, and the CPU resumes execution at that instruction.
Typically, it is not important to know all the details about how the call stack works. However, understanding that functions are effectively pushed on the stack when they are called and popped off when they return gives you the fundamentals needed to understand recursion, as well as some other concepts that are useful when debugging.
Stack overflow
The stack has a limited size, and consequently can only hold a limited amount of information. I
If the program tries to put too much information on the stack, stack overflow will result.
Stack overflow happens when all the memory in the stack has been allocated — in that case, further allocations begin overflowing into other sections of memory.
Stack overflow is generally the result of allocating too many variables on the stack, and/or making too many nested function calls (where function A calls function B calls function C calls function D etc…) Overflowing the stack generally causes the program to crash.
Here is an example program that causes a stack overflow. You can run it on your system and watch it crash:
int main()
{
int nStack[100000000];
return 0;
}
This program tries to allocate a huge array on the stack. Because the stack is not large enough to handle this array, the array allocation overflows into portions of memory the program is not allowed to use. Consequently, the program crashes.
The stack has advantages and disadvantages:
Memory allocated on the stack stays in scope as long as it is on the stack. It is destroyed when it is popped off the stack.
All memory allocated on the stack is known at compile time. Consequently, this memory can be accessed directly through a variable.
Because the stack is relatively small, it is generally not a good idea to do anything that eats up lots of stack space. This includes allocating large arrays, structures, and classes, as well as heavy recursion.
Stack:
Stored in computer RAM like the heap.
Variables created on the stack will go out of scope and automatically deallocate.
Much faster to allocate in comparison to variables on the heap.
Implemented with an actual stack data structure.
Stores local data, return addresses, used for parameter passing
Can have a stack overflow when too much of the stack is used. (mostly from inifinite (or too much) recursion, very large allocations)
Data created on the stack can be used without pointers.
You would use the stack if you know exactly how much data you need to allocate before compile time and it is not too big.
Usually has a maximum size already determined when your program starts
Heap:
Stored in computer RAM like the stack.
Variables on the heap must be destroyed manually and never fall out of scope. The data is freed with delete, delete[] or free
Slower to allocate in comparison to variables on the stack.
Used on demand to allocate a block of data for use by the program.
Can have fragmentation when there are a lot of allocations and deallocations
In C++ data created on the heap will be pointed to by pointers and allocated with new or malloc
Can have allocation failures if too big of a buffer is requested to be allocated.
You would use the heap if you don't know exactly how much data you will need at runtime or if you need to allocate a lot of data.
Responsible for memory leaks
Can you overload new operator
#include<iostream>
#include<malloc.h>
using namespace std;
class sample
{
int i;
char c;
public:
void* operator new(size_t s,int ii,char cc)
{
sample *q =(sample*) malloc(s);
q->i =ii;
q->c =cc;
cout<<"Memory allocation"<<endl;
return q;
}
void operator delete(void *q)
{
free(q);
}
void display()
{ cout<<i<<" "<<c;
}
};
int main()
{
sample *s =new (7,'a')sample;
return 0;
}
when-do-you-overload-operator-new
What is mean of size_t and why we need it.
size_t is type of unsigned integer.which is the Return value of sizeof operator.
`size_t' is a type suitable for representing the amount of memory a data object requires, expressed in units of `char'.
It is an integer type (C cannot keep track of fractions of a `char'), and it is unsigned (negative sizes make no sense). It is the type of the result of the `sizeof' operator. It is the type you pass to malloc() and friends to say how much memory you want.
It is the type returned by strlen() to say how many "significant" characters are in a string.
Each implementation chooses a "real" type like `unsigned int' or `unsigned long' (or perhaps something else)
to be its `size_t', depending on what makes the most sense. You don't usually need to worry about what
`size_t' looks like "under the covers;" all you care about is that it is the "right" type for representing object sizes.
The implementation "publishes" its own choice of `size_t' in several of the Standard headers: <stdio.h>, <stdlib.h>, and some others. If you examine one of these headers (most implementations have some way of doing this), you are likely to find something like
#ifndef __SIZE_T
#define __SIZE_T
typedef unsigned int size_t;
#endif
.... meaning that on this particular implementation `size_t' is an `unsigned int'. Other implementations make other choices.
(The preprocessor stuff -- which needn't be in exactly the form shown here -- ensures that your program will contain only one `typedef' for `size_t' even if it includes several of the headers that declare it)
The complexity of sorting algorithm
Pointers, arrays, and string literals
void strtoupper(char *str)
{
if (str) { // null ptr check, courtesy of Michael
while (*str != '\0') {
// destructively modify the contents at the current pointer location
// using the dereference operator to access the value at the current
// pointer address.
*str = toupper(*str);
++str;
}
}
}
my_str is actually a pointer to a block of memory holding chars. This allows us to use address math to access indices of the array and modify them using the dereference operator. In fact, an array index such as my_str[3] is identical to the expression *(my_str + 3).
char my_str[] = "hello world";
*my_str = toupper(*my_str);
*(my_str + 6) = toupper(*(my_str + 6));
printf("%s", my_str); // prints, "Hello World"
However, if my_str is declared as a char pointer to the string literal “hello world” rather than a char array, these operations fail:
char *my_str = "hello world";
*my_str = toupper(*my_str); // fails
*(my_str + 6) = toupper(*(my_str + 6)); // fails
printf("%s", my_str);
Let’s explore the difference between the two declarations.
char *a = "hello world";
char b[] = "hello world";
In the compiled program, it is likely that “hello world” is stored literally inside the executable. It is effectively an immutable, constant value. Pointing char *a to it provides the scope with read-only access to an immutable block of memory. Therefore, attempting to assign a value might cause other code that points to the same memory to behave erratically.
The declaration of char b[] instead declares a locally allocated block of memory that is then filled with the chars, “hello world”. b is now a pointer to the first address of that array. The complete statement, combining the declaration and assignment, is shorthand. Dispensing with the array size (e.g., char instead of char[12]) is permitted as the compiler is able to ascertain its size from the string literal it was assigned.
In both cases the pointer is used to access array indices:
int i;
for (i = 0; a[i] != '\0'; ++i)
printf("%c", toupper(a[i]));
However, only with b is the program able to modify the values in memory, since it is explicitly copied to a mutable location on the stack in its declaration:
int i;
for (i = 0; b[i] != '\0'; ++i)
b[i] = toupper(b[i]);
printf("%s", b);
Binary Search
A fast way to search a sorted array is to use a binary search. The idea is to look at the element in the middle. If the key is equal to that, the search is finished. If the key is less than the middle element, do a binary search on the first half. If it's greater, do a binary search of the second half.
Performance
The advantage of a binary search over a linear search is astounding for large numbers. For an array of a million elements, binary search, O(log N), will find the target element with a worst case of only 20 comparisons. Linear search, O(N), on average will take 500,000 comparisons to find the element. Probably the only faster kind of search uses hashing, a topic that isn't covered in these notes.
This performance comes at a price - the array must be sorted first. Because sorting isn't a fast operation, it may not be worth the effort to sort when there are only a few searches.
int main()
{
char my_str[] = "hello world";
strtoupper(my_str);
printf("%s", my_str);
return 0;
}
Boost Libraries
The name should already give it away
A Smart Pointer is a C++ object that acts like a pointer, but additionally deletes the object when it is no longer needed.
No longer needed" is hard to define, since resource management in C++ is very complex.
Different smart pointer implementations cover the most common scenarios
Many libraries provide smart pointer implementations with different advantages and drawbacks. The samples here use the BOOST library, a high quality open source template library, with many submissions considered for inclusion in the next C++ standard.
Boost provides the following smart pointer implementations:
The samples use a helper class,
The following sample uses a
This is especially tiresome (and easily forgotten) when using exceptions.The second example uses a
The "normal" reference counted pointer provided by boost is
The
When declaring or using a
E.g., you do only a forward declaration using
But do not yet define how
There are virtually no requirements towards
So you can store objects that need a different cleanup than
If a type
shared_ptr<T> | pointer to T" using a reference count to determine when the object is no longer needed. shared_ptr is the generic, most versatile smart pointer offered by boost. |
scoped_ptr<T> | a pointer automatically deleted when it goes out of scope. No assignment possible, but no performance penalties compared to "raw" pointers |
intrusive_ptr<T> | another reference counting pointer. It provides better performance than shared_ptr, but requires the type T to provide its own reference counting mechanism. |
weak_ptr<T> | a weak pointer, working in conjunction with shared_ptr to avoid circular references |
shared_array<T> | like shared_ptr, but access syntax is for an Array of T |
scoped_array<T> | like scoped_ptr, but access syntax is for an Array of T |
The first: boost::scoped_ptr<T>
scoped_ptr is the simplest smart pointer provided by boost. It guarantees automatic deletion when the pointer goes out of scope.
The samples use a helper class, CSample, that prints diagnostic messages when it it constructed,assigned, or destroyed.
Still it might be interesting to step through with the debugger
The following sample uses a scoped_ptr for automatic destruction
| Using normal pointers | Using scoped_ptr |
void Sample1_Plain() { CSample * pSample(new CSample); if (!pSample->Query() ) // just some function... { delete pSample; return; } pSample->Use(); delete pSample; } | #include "boost/smart_ptr.h" void Sample1_ScopedPtr() { boost::scoped_ptr<CSample> samplePtr(new CSample); if (!samplePtr->Query() ) // just some function... return; samplePtr->Use(); } |
Using "normal" pointers, we must remember to delete it at every place we exit the function.
This is especially tiresome (and easily forgotten) when using exceptions.The second example uses a scoped_ptr for the same task.
It automatically deletes the pointer when the function eturns 8 even in the case of an exception thrown, which isn't even covered in the "raw pointer" sample!
The advantage is obvious: in a more complex function it's easy to forget to delete an object.
scoped_ptr does it for you.Also, when dereferencing a NULL pointer, you get an assertion in debug mode.
| use for | automatic deletion of local objects or class members1, Delayed Instantiation, implementing PIMPL and RAII (see below) |
| not good for | element in an STL container, multiple pointers to the same object |
| performance: | scoped_ptr adds little (if any) overhead to a "plain" pointer, it performs |
shared_ptr<T>
Reference counting pointers track how many pointers are referring to an object.and when the last pointer to an object is destroyed, it deletes the object itself, too.
The "normal" reference counted pointer provided by boost is shared_ptr (the name indicates that multiple pointers can share the same object).
Let's look at a few examples:
void Sample2_Shared() { // (A) create a new CSample instance with one reference boost::shared_ptr<CSample> mySample(new CSample); printf("The Sample now has %i references\n", mySample.use_count()); // should be 1 // (B) assign a second pointer to it: boost::shared_ptr<CSample> mySample2 = mySample; // should be 2 refs by now printf("The Sample now has %i references\n", mySample.use_count()); // (C) set the first pointer to NULL mySample.reset(); printf("The Sample now has %i references\n", mySample2.use_count()); // 1 // the object allocated in (1) is deleted automatically // when mySample2 goes out of scope }
Line (A) creates a new CSample instance on the heap,
and assigns the pointer to ashared_ptr,mySample. Things look like this
Then, we assign it to a second pointer mySample2. Now, two pointers access the same data:
We reset the first pointer (equivalent to p=NULL for a raw pointer).
TheCSampleinstance is still there, sincemySample2holds a reference to it
Only when the last reference,mySample2, goes out of scope, theCSampleis destroyed with it:
Of course, this is not limited to a single CSample instance, or two pointers, or a single function.
Here are some use cases for a shared_ptr.
use in containers using the pointer-to-implementation idiom (PIMPL) Resource-Acquisition-Is-Initialization (RAII) idiom Separating Interface from Implementation
Important Features
The boost::shared_ptr implementation has some important features.
that make it stand out from other implementations
shared_ptr<T> works with an incomplete type
When declaring or using a shared_ptr<T>, T may be an "incomplete type"
E.g., you do only a forward declaration using class T;
But do not yet define how T really looks like.
shared_ptr<T> works with any type:
There are virtually no requirements towards T (such as deriving from a base class)
shared_ptr<T> supports a custom deleter
So you can store objects that need a different cleanup than delete p.For more information, see the boost documentation.
Implicit conversion:
If a type U * can be implicitly converted to T * (e.g., because T is base class of U), a shared_ptr<U> can also be converted to shared_ptr<T> implicitly.
shared_ptr is thread safe
(This is a design choice rather than an advantage, however, it is a necessity in multithreaded programs, and the overhead is low.)
Example: Using shared_ptr in containers
Many container classes, including the STL containers, require copy operations
e.g., when inserting an existing element into a list vector, or container). However,
when this copy operations are expensive (or are even unavailable),
the typical solution is to use a container of pointers
std::vector<CMyLargeClass *> vec;
vec.push_back( new CMyLargeClass("bigString") );
vec.push_back( new CMyLargeClass("bigString") );
However, this throws the task of memory management back to the caller
We can, however, use a
shared_ptrtypedef boost::shared_ptr<CMyLargeClass> CMyLargeClassPtr;
std::vector<CMyLargeClassPtr> vec;
vec.push_back( CMyLargeClassPtr(new CMyLargeClass("bigString")) );Very similar, but now, the elements get destroyed automatically when the vector is destroyed unless, of course, there's another smart pointer still holding a reference Let's have a look at sample void Sample3_Container()
{
typedef boost::shared_ptr<CSample> CSamplePtr;
// (A) create a container of CSample pointers: std::vector<CSamplePtr> vec;
// (B) add three elements vec.push_back(CSamplePtr(new CSample));
vec.push_back(CSamplePtr(new CSample));
vec.push_back(CSamplePtr(new CSample));
// (C) "keep" a pointer to the second: CSamplePtr anElement = vec[1];
// (D) destroy the vector: vec.clear();
// (E) the second element still exists anElement->Use();
printf("done. cleanup is automatic\n");
// (F) anElement goes out of scope, deleting the last CSample instance}
A few things can go wrong with smart pointers most prominent is an invalid reference count
which deletes the object too early, or not at all
The boost implementation promotes safety, making all "potentially dangerous" operations explicit. So, with a few rules to remember, you are safe
Rule 1: Assign and keep
which deletes the object too early, or not at all
The boost implementation promotes safety, making all "potentially dangerous" operations explicit. So, with a few rules to remember, you are safe
Rule 1: Assign and keep
Assign a newly constructed instance to a smart pointer immediately and then keep it there The smart pointer(s) now own the object, you must not delete it manually, nor can you take it away again This helps to not accidentally delete an object that is still
referenced by a smart pointer, or end up with an invalid reference count.
Rule 2 :
a
a
referenced by a smart pointer, or end up with an invalid reference count.
Rule 2 :
a
_ptr<T> is not a T * - more correctly, there are no implicit conversions between a
T * and a smart pointer to type TThis means:When creating a smart pointer, you explicitly have to write ..._ptr<T> myPtr(new T)You cannot assign a T * to a smart pointer You cannot even write ptr=NULL. Use ptr.reset() for thatTo retrieve the raw pointer, use ptr.get(). Of course, you must not delete this pointer or use it after the smart pointer it comes from is destroyedreset or reassignedUse get() only when you have to pass the pointer to a function that expects a raw pointerYou cannot pass a
T * to a function that expects a _ptr<T> directly. You have to construct a smart pointer explicitly, which also makes it
clear that you transfer ownership of the raw pointer to the smart pointer. (See also Rule 3.)
Rule 2: No circular references
If you have two objects referencing each other through a reference counting pointer
they are never deleted. boost provides
weak_ptr to break such cycles (see below).Rule 3: no temporary shared_ptr
Do not construct temporary
shared_ptr to pass them to functions, always use a named (local) variable.
Cyclic References
Reference counting is a convenient resource management mechanism, it has one fundamental drawback though:
Reference counting is a convenient resource management mechanism, it has one fundamental drawback though:
struct CDad; struct CChild;
typedef boost::shared_ptr<CDad> CDadPtr;
typedef boost::shared_ptr<CChild> CChildPtr;
struct CDad : public CSample
{
CChildPtr myBoy;
};
struct CChild : public CSample
{
CDadPtr myDad;
};
// a "thing" that holds a smart pointer to another "thing":
CDadPtr parent(new CDadPtr);
CChildPtr child(new CChildPtr);
// deliberately create a circular reference:parent->myBoy = child;
child->myDad = dad;
Some Useful url related C++ FAQ
http://www.daniweb.com/forums/thread107723.html
// resetting one ptr...child.reset();
parent still references the
CDad object, which itself references the CChild. The whole thing looks like this:If we now call
dad.reset(), we lose all "contact" with the two objects.But this leaves both with exactly one reference, and the shared pointers
see no reason to delete either of them! We have no access to them anymore but they mutually keep themselves "alive".
This is a memory leak at best; in the worst case, the objects hold even more critical resources
that are not released correctly.
The problem is not solvable with a "better" shared pointer implementation
or at least, only with unacceptable overhead and restrictions
So you have to break that cycle. There are two ways:
Manually break the cycle before you release your last reference to it
When the lifetime of
Dad is known to exceed the lifetime of Child, the child can use a normal (raw) pointer to
Dad. Use a
boost::weak_ptr to break the cycleSolutions (1) and (2) are no perfect solutions but they work with smart pointer libraries that do not offer a
weak_ptr like boost does
No comments:
Post a Comment