A virtual function is a member function of a class, whose functionality can be over-ridden in its derived classes. It is one that is declared as virtual in the base class using the virtual keyword. The virtual nature is inherited in the subsequent derived classes and the virtual keyword need not be re-stated there. The whole function body can be replaced with a new set of implementation in the derived class.
Late Binding
In some programs, it is not possible to know which function will be called until runtime (when the program is run). This is known as late binding (or dynamic binding).
In C++, one way to get late binding is to use function pointers. To review function pointers briefly, a function pointer is a type of pointer that points to a function instead of a variable.
The function that a function pointer points to can be called by using the function call operator (()) on the pointer.
int Add(int nX, int nY)
{return nX + nY;
}
int main()
{// Create a function pointer and make it point to the Add function
int (*pFcn)(int, int) = Add;
cout << pFcn(5, 3) << endl; // add 5 + 3
return 0;
}
Calling a function via a function pointer is also known as an indirect function call.
The following calculator program is functionally identical to the calculator example above, except it uses a function pointer instead of a direct function call
#include <iostream>
using namespace std;
int Add(int nX, int nY)
{return nX + nY;
}
int Subtract(int nX, int nY)
{return nX - nY;
}
int Multiply(int nX, int nY)
{return nX * nY;
}
int main()
{int nX;
cout << "Enter a number: ";
cin >> nX;
int nY;
cout << "Enter another number: ";
cin >> nY;
int nOperation;
do
{
cout << "Enter an operation (0=add, 1=subtract, 2=multiply): ";
cin >> nOperation;
} while (nOperation < 0 ||nOperation > 2);
// Create a function pointer named pFcn (yes, the syntax is ugly)
int (*pFcn)(int, int);
// Set pFcn to point to the function the user chose
switch (nOperation)
{
case 0: pFcn = Add; break;
case 1: pFcn = Subtract; break;
case 2: pFcn = Multiply; break;
}
// Call the function that pFcn is pointing to with nX and nY as parameters
cout << "The answer is: " << pFcn(nX, nY) << endl;
return 0;
}
In this example, instead of calling the Add(), Subtract(), or Multiply() function directly, we’ve instead set pFcn to point at the function we wish to call. Then we call the function through the pointer. The compiler is unable to use early binding to resolve the function call pFcn(nX, nY) because it can not tell which function pFcn will be pointing to at compile time!
Late binding is slightly less efficient since it involves an extra level of indirection. With early binding, the compiler can tell the CPU to jump directly to the function’s address. With late binding, the program has to read the address held in the pointer and then jump to that address. This involves one extra step, making it slightly slower. However, the advantage of late binding is that it is more flexible than early binding, because decisions about what function to call do not need to be made until run time.
In Short
Whenever a program has a virtual function declared, a v - table is constructed for the class. The v-table consists of addresses to the virtual functions forclasses that contain one or more virtual functions.
The object of the class containing the virtual function contains a virtual pointer that points to the base address of the virtual table in memory. Whenever there is a virtual function call, the v-table is used to resolve to the function address.
An object of the class that contains one or more virtual functions contains a virtual pointer called the vptr at the very beginning of the object in the memory. Hence the size of the object in this case increases by the size of the pointer.
This vptr containsthe base address of the virtual table in memory. Note that virtual tables are class specific, i.e., there is only one virtual table for a class irrespective of the number of virtual functions it contains.
This virtual table in turn containsthe base addresses of one or more virtual functions of the class. At the time when a virtual function is called on an object, the vptr of that object provides the base address of the virtual table for that class in memory.
So complier generate the code to extract first two bytes of the object whose address is stored in the pointer
(i.e p =&d) This gives the address of the VTABLE. The complier also adds a number to this address.
This number is actually an offset in VTABLE. we determine the call.
This table is used to resolve the function call as it contains the addresses of all the virtual functions of that class. This is how dynamic binding is resolved during a virtual function call.
In detail
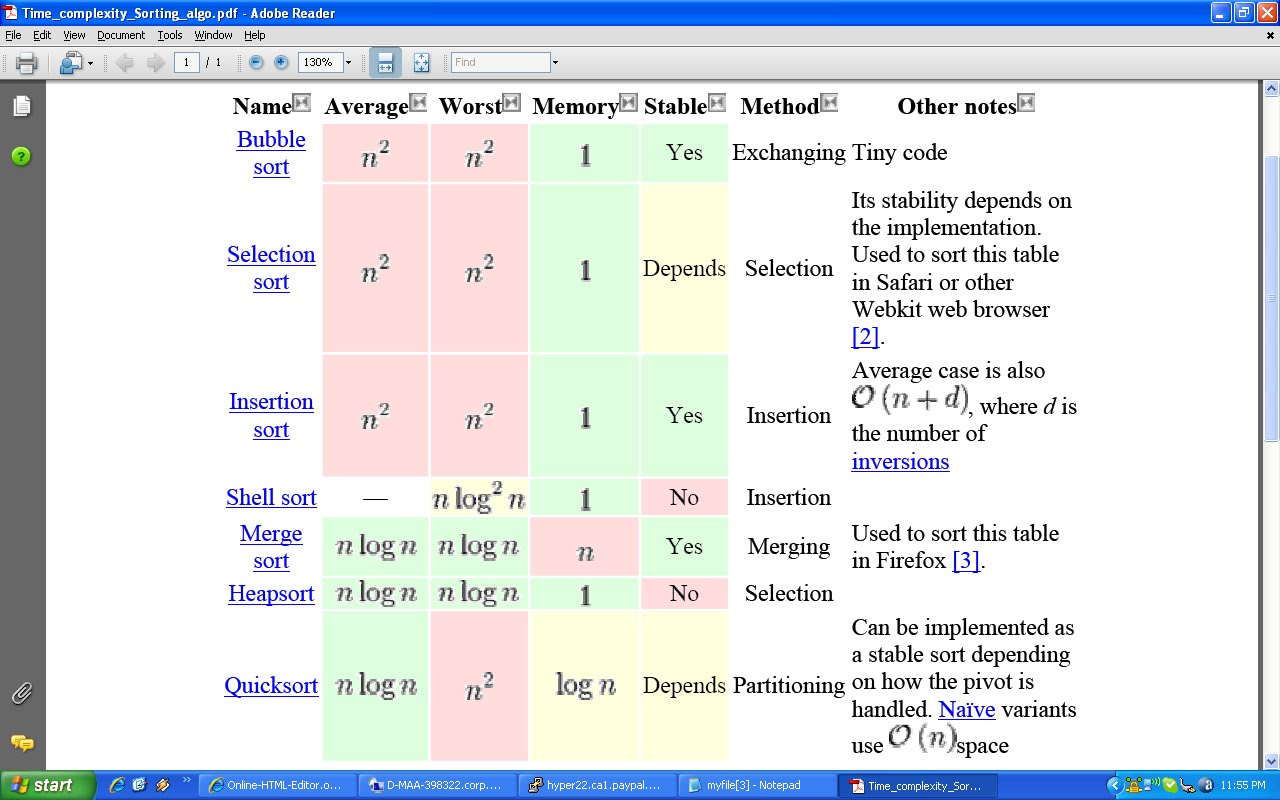
The virtual table is actually quite simple, though it’s a little complex to describe in words. First, every class
that uses virtual functions (or is derived from a class that uses virtual functions) is given it’s own virtual table.
This table is simply a static array that the compiler sets up at compile time. A virtual table contains one entry for each virtual function that can be called by objects of the class. Each entry in this table is simply a function pointer that points to the most-derived function accessible by that class.
Second, the compiler also adds a hidden pointer to the base class, which we will call *__vptr. *__vptr is set (automatically) when a class instance is created so that it points to the virtual table for that class.
Unlike the *this pointer, which is actually a function parameter used by the compiler to resolve self-references, *__vptr is a real pointer. Consequently, it makes each class object allocated bigger by the size of one pointer.
It also means that *__vptr is inherited by derived classes, which is important.
Ex..
class Base
{
public:
virtual void function1() {};
virtual void function2() {};
};
class D1: public Base
{
public:
virtual void function1() {};
};
class D2: public Base
{
public:
virtual void function2() {};
};
Because there are 3 classes here, the compiler will set up 3 virtual tables: one for Base, one for D1, and one for D2
The compiler also adds a hidden pointer to the most base class that uses virtual functions. Although the compiler does this automatically, we’ll put it in the next example just to show where it’s added
class Base
{
public:
FunctionPointer *__vptr;
virtual void function1() {};
virtual void function2() {};
};
class D1: public Base
{
public:
virtual void function1() {};
};
class D2: public Base
{
public:
virtual void function2() {};
};
When a class object is created, *__vptr is set to point to the virtual table for that class. For example, when a object of type Base is created, *__vptr is set to point to the virtual table for Base. When objects of type D1 or D2 are constructed, *__vptr is set to point to the virtual table for D1 or D2 respectively.
Now, let’s talk about how these virtual tables are filled out. Because there are only two virtual functions here, each virtual table will have two entries (one for function1(), and one for function2()). Remember that when these virtual tables are filled out, each entry is filled out with the most-derived function an object of that class type can call.
Base’s virtual table is simple. An object of type Base can only access the members of Base. Base has no access to D1 or D2 functions. Consequently, the entry for function1 points to Base::function1(), and the entry for function2 points to Base::function2().
D1’s virtual table is slightly more complex. An object of type D1 can access members of both D1 and Base. However, D1 has overridden function1(), making D1::function1() more derived than Base::function1(). Consequently, the entry for function1 points to D1::function1(). D1 hasn’t overridden function2(), so the entry for function2 will point to Base::function2().
D2’s virtual table is similar to D1, except the entry for function1 points to Base::function1(), and the entry for function2 points to D2::function2().
consider what happens when we create an object of type D1:
int main()
{
D1 cClass;
}
Because cClass is a D1 object, cClass has it’s *__vptr set to the D1 virtual table.
Now, let’s set a base pointer to D1:
int main()
{
D1 cClass;
Base *pClass = &cClass;
}
Note that because pClass is a base pointer, it only points to the Base portion of cClass. However, also note that *__vptr is in the Base portion of the class, so pClass has access to this pointer. Finally, note that pClass->__vptr points to the D1 virtual table! Consequently, even though pClass is of type Base, it still has access to D1’s virtual table.
So what happens when we try to call pClass->function1()?
int main()
{
D1 cClass;
Base *pClass = &cClass;
pClass->function1();
}
First, the program recognizes that function1() is a virtual function. Second, uses pClass->__vptr to get to D1’s virtual table. Third, it looks up which version of function1() to call in D1’s virtual table. This has been set to D1::function1(). Therefore, pClass->function1() resolves to D1::function1()!
Now, you might be saying, “But what if Base really pointed to a Base object instead of a D1 object. Would it still call D1::function1()?”. The answer is no.
int main()
{
Base cClass;
Base *pClass = &cClass;
pClass->function1();
}
In this case, when cClass is created, __vptr points to Base’s virtual table, not D1’s virtual table. Consequently, pClass->__vptr will also be pointing to Base’s virtual table. Base’s virtual table entry for function1() points to Base::function1(). Thus, pClass->function1() resolves to Base::function1(), which is the most-derived version of function1() that a Base object should be able to call.
By using these tables, the compiler and program are able to ensure function calls resolve to the appropriate virtual function, even if you’re only using a pointer or reference to a base class!
Calling a virtual function is slower than calling a non-virtual function for a couple of reasons: First, we have to use the *__vptr to get to the appropriate virtual table. Second, we have to index the virtual table to find the correct function to call. Only then can we call the function. As a result, we have to do 3 operations to find the function to call, as opposed to 2 operations for a normal indirect function call, or one operation for a direct function call. However, with modern computers, this added time is usually fairly insignificant
Function overloading
Function overloading is a feature of C++ that allows us to create multiple functions with the same name, so long as they have different parameters. Consider the following function:
Function overloading provides a better solution. Using function overloading, we can declare another Add() function that takes double parameters:
Consequently, it’s also possible to define Add() functions with a differing number of parameters:
Note that the function’s return type is NOT considered when overloading functions. Consider the case where you want to write a function that returns a random number, but you need a version that will return an int, and another version that will return a double. You might be tempted to do this:
Also keep in mind that declaring a typedef does not introduce a new type — consequently, the following the two declarations of Print() are considered identical:
Enum is promoted to int
void Print(char *szValue);
void Print(int nValue);
Print('a'); // promoted to match Print(int)
In this case, because there is no Print(char), the char ‘a’ is promoted to an integer, which then matches Print(int).
3) If no promotion is found, C++ tries to find a match through standard conversion. Standard conversions include:
Any numeric type will match any other numeric type, including unsigned (eg. int to float)
Enum will match the formal type of a numeric type (eg. enum to float)
Zero will match a pointer type and numeric type (eg. 0 to char*, or 0 to float)
A pointer will match a void pointer
void Print(float fValue);
void Print(struct sValue);
Print('a'); // promoted to match Print(float)
Note that all standard conversions are considered equal.
No standard conversion is considered better than any of the others
Finally, C++ tries to find a match through user-defined conversion. Although we have not covered classes yet, classes (which are similar to structs) can define conversions to other types that can be implicitly applied to objects of that class. For example, we might define a class X and a user-defined conversion to int.
Function Pointer
virtual table structure in pure virtual function case
virtual function FAQ
some more FAQ about virtual
size of class object
1. Where the virtual table reside into memory
2. what will happen if we have virtual keyword in derived class
5 . vpointer inherited into the inheritance
6. what is pure virtual function/abstract class
Late Binding
In some programs, it is not possible to know which function will be called until runtime (when the program is run). This is known as late binding (or dynamic binding).
In C++, one way to get late binding is to use function pointers. To review function pointers briefly, a function pointer is a type of pointer that points to a function instead of a variable.
The function that a function pointer points to can be called by using the function call operator (()) on the pointer.
int Add(int nX, int nY)
{return nX + nY;
}
int main()
{// Create a function pointer and make it point to the Add function
int (*pFcn)(int, int) = Add;
cout << pFcn(5, 3) << endl; // add 5 + 3
return 0;
}
Calling a function via a function pointer is also known as an indirect function call.
The following calculator program is functionally identical to the calculator example above, except it uses a function pointer instead of a direct function call
#include <iostream>
using namespace std;
int Add(int nX, int nY)
{return nX + nY;
}
int Subtract(int nX, int nY)
{return nX - nY;
}
int Multiply(int nX, int nY)
{return nX * nY;
}
int main()
{int nX;
cout << "Enter a number: ";
cin >> nX;
int nY;
cout << "Enter another number: ";
cin >> nY;
int nOperation;
do
{
cout << "Enter an operation (0=add, 1=subtract, 2=multiply): ";
cin >> nOperation;
} while (nOperation < 0 ||nOperation > 2);
// Create a function pointer named pFcn (yes, the syntax is ugly)
int (*pFcn)(int, int);
// Set pFcn to point to the function the user chose
switch (nOperation)
{
case 0: pFcn = Add; break;
case 1: pFcn = Subtract; break;
case 2: pFcn = Multiply; break;
}
// Call the function that pFcn is pointing to with nX and nY as parameters
cout << "The answer is: " << pFcn(nX, nY) << endl;
return 0;
}
In this example, instead of calling the Add(), Subtract(), or Multiply() function directly, we’ve instead set pFcn to point at the function we wish to call. Then we call the function through the pointer. The compiler is unable to use early binding to resolve the function call pFcn(nX, nY) because it can not tell which function pFcn will be pointing to at compile time!
Late binding is slightly less efficient since it involves an extra level of indirection. With early binding, the compiler can tell the CPU to jump directly to the function’s address. With late binding, the program has to read the address held in the pointer and then jump to that address. This involves one extra step, making it slightly slower. However, the advantage of late binding is that it is more flexible than early binding, because decisions about what function to call do not need to be made until run time.
In Short
Whenever a program has a virtual function declared, a v - table is constructed for the class. The v-table consists of addresses to the virtual functions forclasses that contain one or more virtual functions.
The object of the class containing the virtual function contains a virtual pointer that points to the base address of the virtual table in memory. Whenever there is a virtual function call, the v-table is used to resolve to the function address.
An object of the class that contains one or more virtual functions contains a virtual pointer called the vptr at the very beginning of the object in the memory. Hence the size of the object in this case increases by the size of the pointer.
This vptr containsthe base address of the virtual table in memory. Note that virtual tables are class specific, i.e., there is only one virtual table for a class irrespective of the number of virtual functions it contains.
This virtual table in turn containsthe base addresses of one or more virtual functions of the class. At the time when a virtual function is called on an object, the vptr of that object provides the base address of the virtual table for that class in memory.
So complier generate the code to extract first two bytes of the object whose address is stored in the pointer
(i.e p =&d) This gives the address of the VTABLE. The complier also adds a number to this address.
This number is actually an offset in VTABLE. we determine the call.
This table is used to resolve the function call as it contains the addresses of all the virtual functions of that class. This is how dynamic binding is resolved during a virtual function call.
In detail
The virtual table is actually quite simple, though it’s a little complex to describe in words. First, every class
that uses virtual functions (or is derived from a class that uses virtual functions) is given it’s own virtual table.
This table is simply a static array that the compiler sets up at compile time. A virtual table contains one entry for each virtual function that can be called by objects of the class. Each entry in this table is simply a function pointer that points to the most-derived function accessible by that class.
Second, the compiler also adds a hidden pointer to the base class, which we will call *__vptr. *__vptr is set (automatically) when a class instance is created so that it points to the virtual table for that class.
Unlike the *this pointer, which is actually a function parameter used by the compiler to resolve self-references, *__vptr is a real pointer. Consequently, it makes each class object allocated bigger by the size of one pointer.
It also means that *__vptr is inherited by derived classes, which is important.
Ex..
class Base
{
public:
virtual void function1() {};
virtual void function2() {};
};
class D1: public Base
{
public:
virtual void function1() {};
};
class D2: public Base
{
public:
virtual void function2() {};
};
Because there are 3 classes here, the compiler will set up 3 virtual tables: one for Base, one for D1, and one for D2
The compiler also adds a hidden pointer to the most base class that uses virtual functions. Although the compiler does this automatically, we’ll put it in the next example just to show where it’s added
class Base
{
public:
FunctionPointer *__vptr;
virtual void function1() {};
virtual void function2() {};
};
class D1: public Base
{
public:
virtual void function1() {};
};
class D2: public Base
{
public:
virtual void function2() {};
};
When a class object is created, *__vptr is set to point to the virtual table for that class. For example, when a object of type Base is created, *__vptr is set to point to the virtual table for Base. When objects of type D1 or D2 are constructed, *__vptr is set to point to the virtual table for D1 or D2 respectively.
Now, let’s talk about how these virtual tables are filled out. Because there are only two virtual functions here, each virtual table will have two entries (one for function1(), and one for function2()). Remember that when these virtual tables are filled out, each entry is filled out with the most-derived function an object of that class type can call.
Base’s virtual table is simple. An object of type Base can only access the members of Base. Base has no access to D1 or D2 functions. Consequently, the entry for function1 points to Base::function1(), and the entry for function2 points to Base::function2().
D1’s virtual table is slightly more complex. An object of type D1 can access members of both D1 and Base. However, D1 has overridden function1(), making D1::function1() more derived than Base::function1(). Consequently, the entry for function1 points to D1::function1(). D1 hasn’t overridden function2(), so the entry for function2 will point to Base::function2().
D2’s virtual table is similar to D1, except the entry for function1 points to Base::function1(), and the entry for function2 points to D2::function2().

consider what happens when we create an object of type D1:
int main()
{
D1 cClass;
}
Because cClass is a D1 object, cClass has it’s *__vptr set to the D1 virtual table.
Now, let’s set a base pointer to D1:
int main()
{
D1 cClass;
Base *pClass = &cClass;
}
Note that because pClass is a base pointer, it only points to the Base portion of cClass. However, also note that *__vptr is in the Base portion of the class, so pClass has access to this pointer. Finally, note that pClass->__vptr points to the D1 virtual table! Consequently, even though pClass is of type Base, it still has access to D1’s virtual table.
So what happens when we try to call pClass->function1()?
int main()
{
D1 cClass;
Base *pClass = &cClass;
pClass->function1();
}
First, the program recognizes that function1() is a virtual function. Second, uses pClass->__vptr to get to D1’s virtual table. Third, it looks up which version of function1() to call in D1’s virtual table. This has been set to D1::function1(). Therefore, pClass->function1() resolves to D1::function1()!
Now, you might be saying, “But what if Base really pointed to a Base object instead of a D1 object. Would it still call D1::function1()?”. The answer is no.
int main()
{
Base cClass;
Base *pClass = &cClass;
pClass->function1();
}
In this case, when cClass is created, __vptr points to Base’s virtual table, not D1’s virtual table. Consequently, pClass->__vptr will also be pointing to Base’s virtual table. Base’s virtual table entry for function1() points to Base::function1(). Thus, pClass->function1() resolves to Base::function1(), which is the most-derived version of function1() that a Base object should be able to call.
By using these tables, the compiler and program are able to ensure function calls resolve to the appropriate virtual function, even if you’re only using a pointer or reference to a base class!
Calling a virtual function is slower than calling a non-virtual function for a couple of reasons: First, we have to use the *__vptr to get to the appropriate virtual table. Second, we have to index the virtual table to find the correct function to call. Only then can we call the function. As a result, we have to do 3 operations to find the function to call, as opposed to 2 operations for a normal indirect function call, or one operation for a direct function call. However, with modern computers, this added time is usually fairly insignificant
Function overloading
Function overloading is a feature of C++ that allows us to create multiple functions with the same name, so long as they have different parameters. Consider the following function:
int Add(int nX, int nY)
{
return nX + nY;
}
This trivial function adds two integers. However, what if we also need to add two floating point numbers? This function is not at all suitable, as any floating point parameters would be converted to integers, causing the floating point arguments to lose their fractional values.
int AddI(int nX, int nY)
{
return nX + nY;
}
double AddD(double dX, double dY)
{
return dX + dY;
}
However, for best effect, this requires that you define a consistent naming standard, remember the name of all the different flavors of the function, and call the correct one (calling AddD() with integer parameters may produce the wrong result due to precision issues).
Function overloading provides a better solution. Using function overloading, we can declare another Add() function that takes double parameters:
double Add(double dX, double dY)
{
return dX + dY;
}
We now have two version of Add():
int Add(int nX, int nY); // integer version double Add(double dX, double dY); // floating point version
Which version of Add() gets called depends on the arguments used in the call — if we provide two ints, C++ will know we mean to call Add(int, int). If we provide two floating point numbers, C++ will know we mean to call Add(double, double). In fact, we can define as many overloaded Add() functions as we want, so long as each Add() function has unique parameters.
Consequently, it’s also possible to define Add() functions with a differing number of parameters:
int Add(int nX, int nY, int nZ)
{
return nX + nY + nZ;
}
Even though this Add() function has 3 parameters instead of 2, because the parameters are different than any other version of Add(), this is valid.
Note that the function’s return type is NOT considered when overloading functions. Consider the case where you want to write a function that returns a random number, but you need a version that will return an int, and another version that will return a double. You might be tempted to do this:
int GetRandomValue();
double GetRandomValue();
But the compiler will flag this as an error. These two functions have the same parameters (none), and consequently, the second GetRandomValue() will be treated as an erroneous redeclaration of the first.
Consequently, these functions will need to be given different names.
Consequently, these functions will need to be given different names.
Also keep in mind that declaring a typedef does not introduce a new type — consequently, the following the two declarations of Print() are considered identical:
typedef char *string;
void Print(string szValue);
void Print(char *szValue);
How function calls are matched with overloaded functions
Making a call to an overloaded function results in one of three possible outcomes:
1) A match is found. The call is resolved to a particular overloaded function.
2)No match is found. The arguments can not be matched to any overloaded function.
3)An ambiguous match is found. The arguments matched more than one overloaded function.
When an overloaded function is called, C++ goes through the following
process to determine which version of the function will be called
1) First, C++ tries to find an exact match. This is the case where the
actual argument exactly matches the parameter type of one of the
overloaded functions. For example:
void Print(char *szValue);
void Print(int nValue);
Print(0); // exact match with Print(int)
Although 0 could technically match Print(char*), it exactly matches Print(int).
Thus Print(int) is the best match available.
2) If no exact match is found, C++ tries to find a match through promotion
Char, unsigned char, and short is promoted to an int.
Unsigned short can be promoted to int or unsigned int, depending on the size of an int
Float is promoted to double
Enum is promoted to int
void Print(char *szValue);
void Print(int nValue);
Print('a'); // promoted to match Print(int)
In this case, because there is no Print(char), the char ‘a’ is promoted to an integer, which then matches Print(int).
3) If no promotion is found, C++ tries to find a match through standard conversion. Standard conversions include:
Any numeric type will match any other numeric type, including unsigned (eg. int to float)
Enum will match the formal type of a numeric type (eg. enum to float)
Zero will match a pointer type and numeric type (eg. 0 to char*, or 0 to float)
A pointer will match a void pointer
void Print(float fValue);
void Print(struct sValue);
Print('a'); // promoted to match Print(float)
Note that all standard conversions are considered equal.
No standard conversion is considered better than any of the others
Finally, C++ tries to find a match through user-defined conversion. Although we have not covered classes yet, classes (which are similar to structs) can define conversions to other types that can be implicitly applied to objects of that class. For example, we might define a class X and a user-defined conversion to int.
class X; // with user-defined conversion to int
void Print(float fValue);
void Print(int nValue);
X cValue; // declare a variable named cValue of type class X
Print(cValue); // cValue will be converted to an int and matched to Print(int)
Function Pointer
virtual table structure in pure virtual function case
virtual function FAQ
some more FAQ about virtual
size of class object
1. Where the virtual table reside into memory
- http://stackoverflow.com/questions/10387691/where-is-the-virtual-function-table-for-c-class-stored
- http://stackoverflow.com/questions/1905237/where-in-memory-is-vtable-stored
2. what will happen if we have virtual keyword in derived class
- if you not have define virtual function in base class and define into derive class than virtual functionality does not work
- http://stackoverflow.com/questions/4895294/c-virtual-keyword-for-functions-in-derived-classes-is-it-necessary
- vpointer is part of object
- http://stackoverflow.com/questions/706861/where-does-intel-c-compiler-store-the-vptr-pointer-to-virtual-function-table
The precise location of the vptr (the pointer to the class's
table of virtual functions' addresses) is implementation-
dependent. Some compilers, e.g., Visual C++ and C++
Builder, place it offset 0, before the user-declared data
members. Other compilers, such as GCC and DEC
CXX, place the vptr at the end of the class,
after all the user-declared data members. Normally,
you wouldn't care about the vptr's position. However, under
certain conditions, for example, in applications that dump
an object's content to a file so that it can be retrieved
afterwards, the vptr's position matters.
To detect it, first take the address of an object that.
Then compare it to the address of the first data member of
that object. If the two addresses are identical, it's likely
that the vptr is located at the end. If, however, the
member's address is higher than the object's address,
this means that the vptr is located at the object's
beginning. To detect where your compiler places the vptr,
run the following program:
class A
{
public:
virtual void f() {}
int n;
};
int main()
{
A a;
char *p1=reinterpret_cast <char *> (&a);
char *p2=reinterpret_cast <char *> (&a.n);
if (p1==p2)
cout<<"vptr is located at the object's
end"<<endl;
else
cout<<"vptr is located at the object's
beginning"<<endl;
}
5 . vpointer inherited into the inheritance
6. what is pure virtual function/abstract class
- http://www.learncpp.com/cpp-tutorial/126-pure-virtual-functions-abstract-base-classes-and-interface-classes/
- http://www.learncpp.com/cpp-tutorial/126-pure-virtual-functions-abstract-base-classes-and-interface-classes/
- http://www.gotw.ca/gotw/031.htm
- compile time error
- Yes
- Refer 3 question
- Refer 2 question
- Refer above question
- Refer above question
- Yes
15. how does Vtable contain the function order for the base and derived class.
- In base class, The function is defined in same way
- In derived class, derive class first and than base class
- Refer above question
- Refer above question
18. Does vptr depend on the class /object
- each class contain vptr and inherited into derive class
- vptr is a part of object
19. How many vptr will create if you have three object of the class
- One vptr
20. Does vptr inherited into derive class
- Yes
21. what is virtual destructor/need of virtual destructor
22. what is virtual base class/need of virtual class
24. what is diamond shape problem in case of virtual function.
28. is it necessary that we should override virtual function
29. Pure virtual function can never a body
30. Does virtual function mechanism work in cosntructor
31, if we do not over ride virtual function in the derived class than will derived class become abstract class.
32. Does derived class has access to private data member of base
33. Can you base class function from the derived class.
34. what is dreaded diamond
35.what are the access rule in terms of inheritance. i mean in terms of accessing of variable.
36. what is final class
1) make a constructor as private (static function can create a object)
2) make a destructor as private
3)
class temp
{
private:
~temp();
friend final_class;
};
class final_class : public virtual temp
{
}
37. virtual table unresolved error.
we should define the in the virtual class
38. Does vtable create in the case of pure virtual function.
39. What is upcasting
40 . what is downcasting.
41. Display VTABLE
- http://www.programmerinterview.com/index.php/c-cplusplus/virtual-destructors/
- http://stackoverflow.com/questions/7750280/how-does-virtual-destructor-work-in-c
- http://www.geeksforgeeks.org/pure-virtual-destructor-c/
class sample
{
public:
virtual void fun();
virtual ~sample()
};
class der : public sample
{
public:
~der();
void fun();
};
int main()
{
sample *p = new derived;
delete p;
}
so it is call the derived class destructor
22. what is virtual base class/need of virtual class
- http://www.learncpp.com/cpp-tutorial/118-virtual-base-classes/
- https://isocpp.org/wiki/faq/multiple-inheritance
- http://stackoverflow.com/questions/21558/in-c-what-is-a-virtual-base-class
- http://www.phpcompiler.org/articles/virtualinheritance.html (Need to look again).
24. what is diamond shape problem in case of virtual function.
- Refer above
- http://www.geeksforgeeks.org/object-slicing-in-c/
- http://stackoverflow.com/questions/274626/what-is-object-slicing#274636
- http://www.bogotobogo.com/cplusplus/slicing.php
28. is it necessary that we should override virtual function
29. Pure virtual function can never a body
30. Does virtual function mechanism work in cosntructor
31, if we do not over ride virtual function in the derived class than will derived class become abstract class.
32. Does derived class has access to private data member of base
33. Can you base class function from the derived class.
34. what is dreaded diamond
35.what are the access rule in terms of inheritance. i mean in terms of accessing of variable.
36. what is final class
1) make a constructor as private (static function can create a object)
2) make a destructor as private
3)
class temp
{
private:
~temp();
friend final_class;
};
class final_class : public virtual temp
{
}
37. virtual table unresolved error.
we should define the in the virtual class
38. Does vtable create in the case of pure virtual function.
39. What is upcasting
40 . what is downcasting.
41. Display VTABLE